 SEOWECHAT
SEOWECHAT前一段时间,好几个做独立站的朋友在群里说同一件事:
产品页一直在上,内容也在更,但Google就是不收录。等了两周,三周,四周,还是没动静。去GSC里一看,“已发现但未索引”。更难受的是,有些页面之前明明收录了,后来又掉了。
没人知道为什么。
大家都往内容质量上想。觉得是不是文案太薄,是不是重复度太高,是不是AI写的被降权了。
但后台一个数据没人查过。
点击路径。
有些产品页,从首页点过去,要点6次。对,6次。分类页套分类页,筛选套筛选,最后一个产品藏在第7层。
你不是内容不行。你是让Google爬不到你。
Crawl depth这件事,很多人以前知道这个概念,但没当回事。觉得只要sitemap交了,Google总会爬的。现在回头看,还是太天真了。
— 1 —
你的站点结构,正在吃掉crawl budget
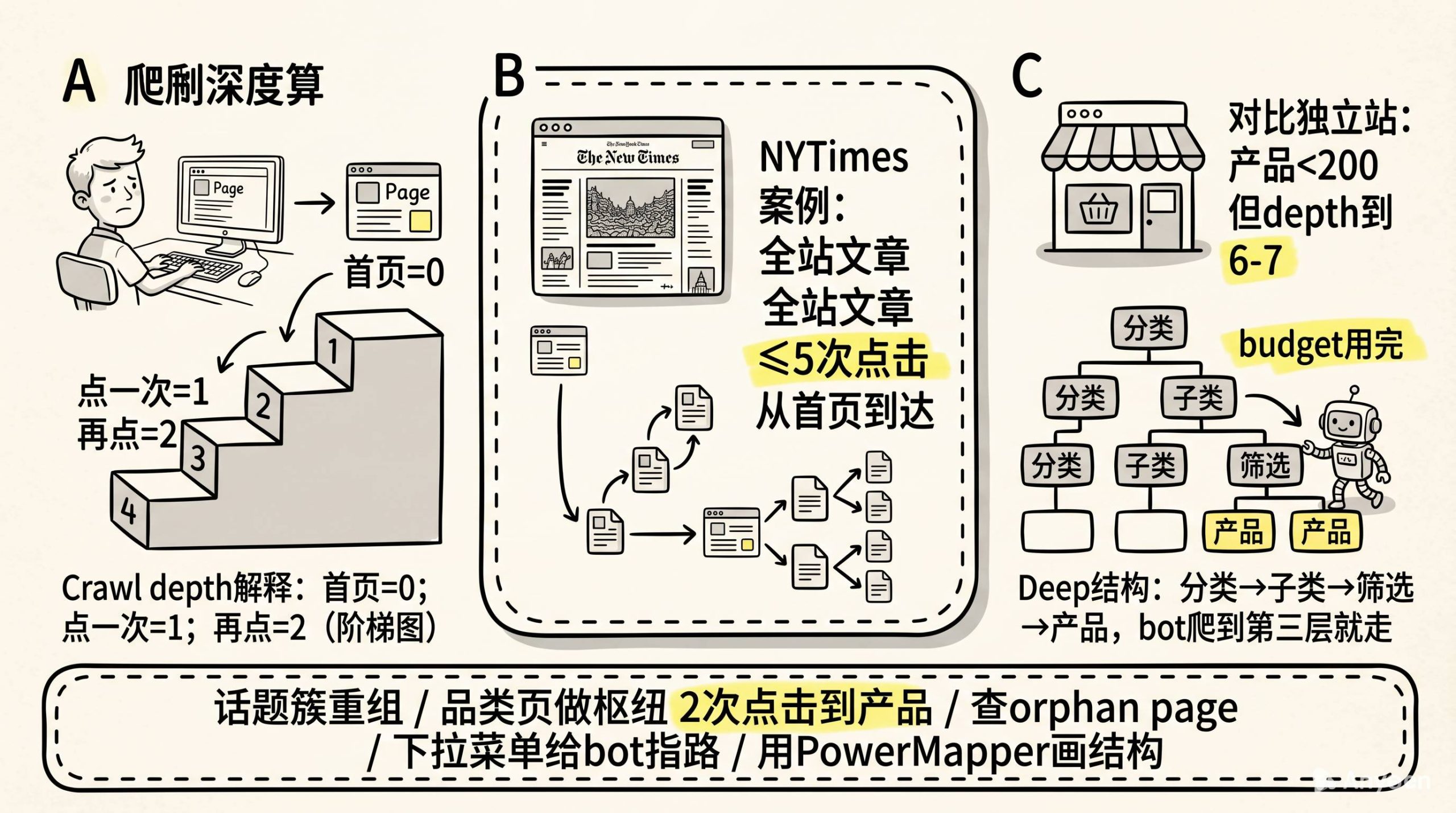
什么是crawl depth?说起来很简单。
首页的crawl depth是0。从首页点一次能到的页面,depth是1。再点一次是2。以此类推。
The New York Times有个数据比价适合当案例:他们从1851年到现在的所有文章,全站没有一篇文章超过5次点击就能从首页到达。
没有一篇。
这是一个120年内容积累的网站做到的事。
而我们很多独立站,去年才上线,产品不到200个,有的页面depth已经到6、7了。
问题出在哪儿?
结构不是“扁”的,是“深”的。一层套一层。分类-子分类-子子分类-筛选-产品。每次点击都往下沉一层。Googlebot来一次,爬到第三层就走了。为什么?crawl budget用完了。
crawl budget不是无限的。Google给你网站每次爬取的页面数量是有限的。如果你把budget浪费在那些depth很深的分类翻页上,真正该被收录的产品页反而轮不到。
怎么改?
-
用话题簇重组内容结构,不要按“我觉得该这样分”来建分类
-
电商站必须用品类页做枢纽,所有产品从品类页最多点2次能到
-
查一遍有没有orphan page(没有任何内部链接指向的页面),这种页面对Google来说根本不存在
-
导航栏的下拉菜单不是装饰,是给bot指路的
如果你不知道自己现在的站点结构长什么样,用PowerMapper跑一遍。跑完你就知道了。有些你以为“结构还不错”的站,跑出来是一团乱麻。
— 2 —
sitemap不是做完就完了
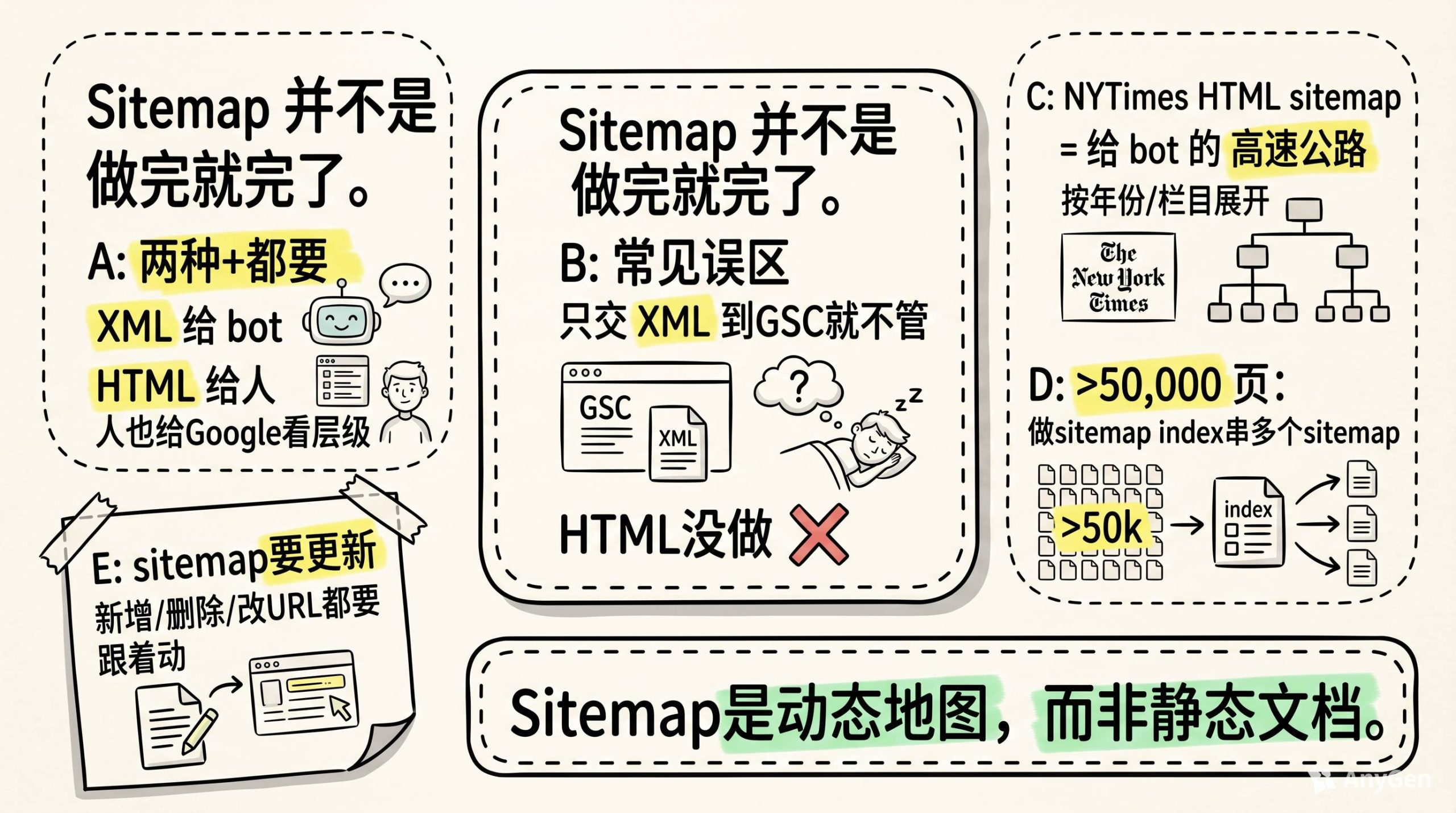
HTML sitemap和XML sitemap,两个都要有。
这不是什么高阶操作。但我见太多独立站,上线时用Yoast自动生成了一个XML sitemap,交到GSC,就再也没管过。
HTML sitemap呢?没做。
Google明确说两种sitemap都要。XML是给bot读的,HTML是给人读的,但HTML同时也在告诉Google你的站点层级是什么。
去看看The New York Times的HTML sitemap。极简,但有效。按年份、按栏目,全部展开。一个普通用户可能一辈子不会点进去,但对bot来说,那是一条高速公路。
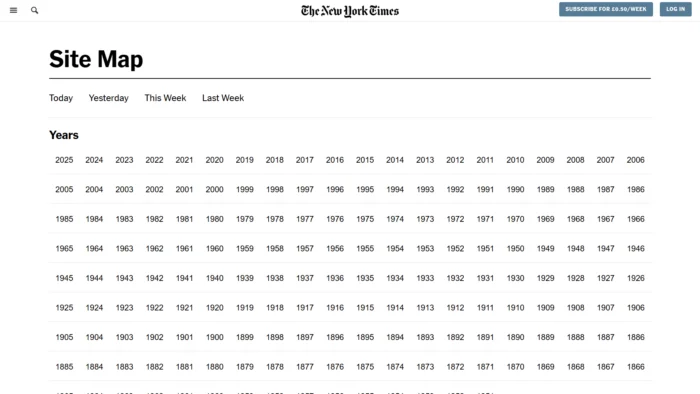
如果你的站点超过50,000个页面,记得做sitemap index page,把多个sitemap串起来。别指望一个sitemap文件把所有页面都列完,那不现实。
还有一件事容易被忽略:sitemap要更新。你上了新页面,删了旧页面,改了URL结构,sitemap得跟着动。不是交一次就完事。
— 3 —
内部链接为什么比你以为的更值钱
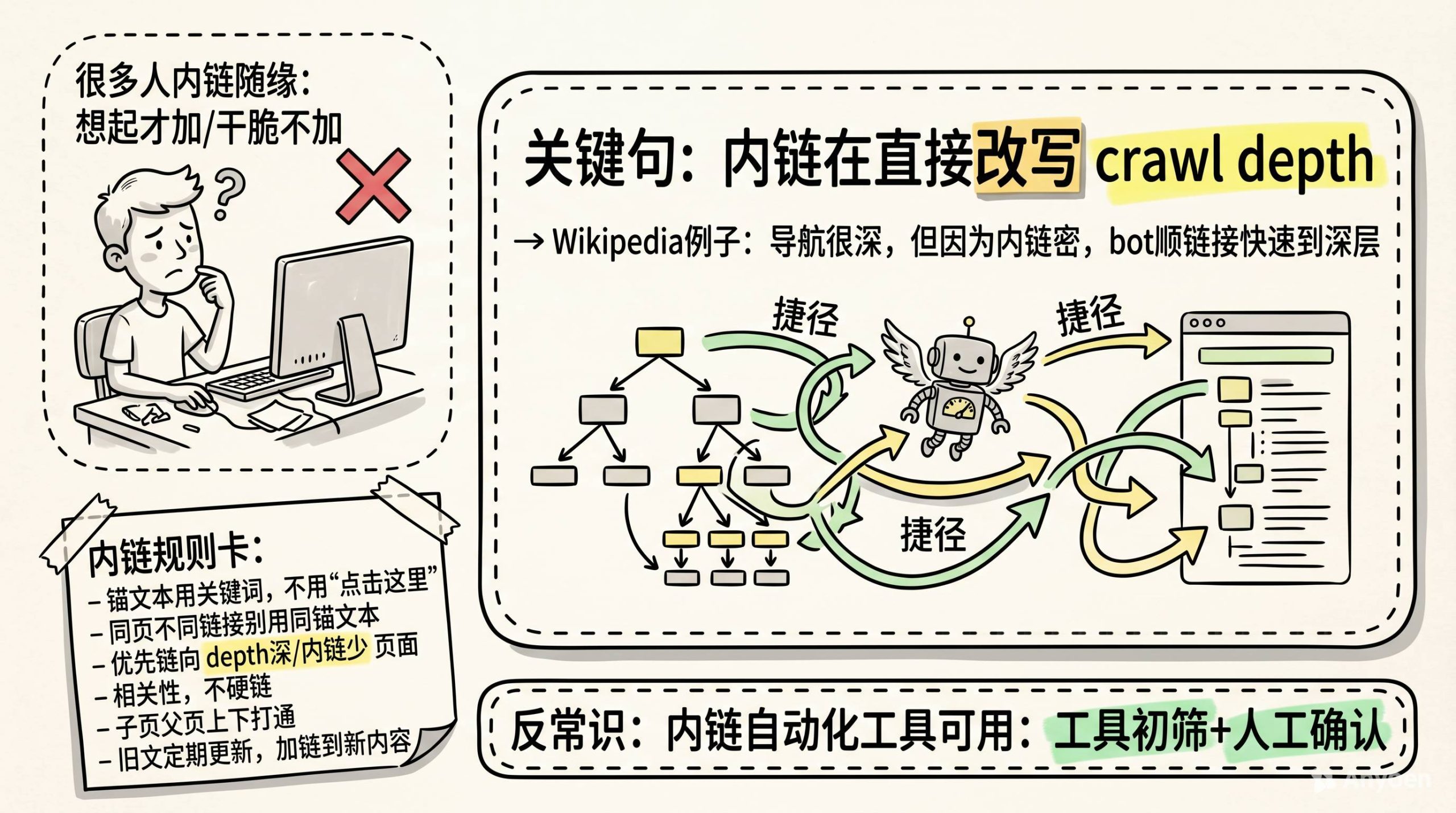
很多人做内链是随机的。
写到一篇新文章,想起来加一两个链接指向相关产品。或者干脆不加。觉得“用户自己会搜”。
但内链是在直接改写你的crawl depth。
举个例子。Wikipedia。
如果你只靠导航栏,Wikipedia上一些冷门词条可能要从首页点十几次才能到。但因为他们内链做得极密,bot顺着页面里的链接就能快速抵达那些深层内容。内链等于在站点内部修了无数条捷径。
内链怎么做好?
-
锚文本用关键词,别用“点击这里”
-
同一页面上,两个不同链接不要用完全相同的锚文本,bot会困惑
-
优先链向crawl depth深、现有内链少的页面,雪中送炭比锦上添花有用
-
链接要有相关性,别硬链
-
记得链子页面和父页面,上下打通
-
旧页面定期更新,加链向新内容的链接
还有一个反常识的点:内链自动化工具可以用。
很多人对自动化有偏见,觉得不自然。但说实话,当你站点有几千上万个页面时,一个人根本不可能手动把内链分配得均匀合理。工具初筛,人工判断确认,这个组合比纯手动效率高太多。
— 4 —
“信息线索”这个词,做独立站的都得想想
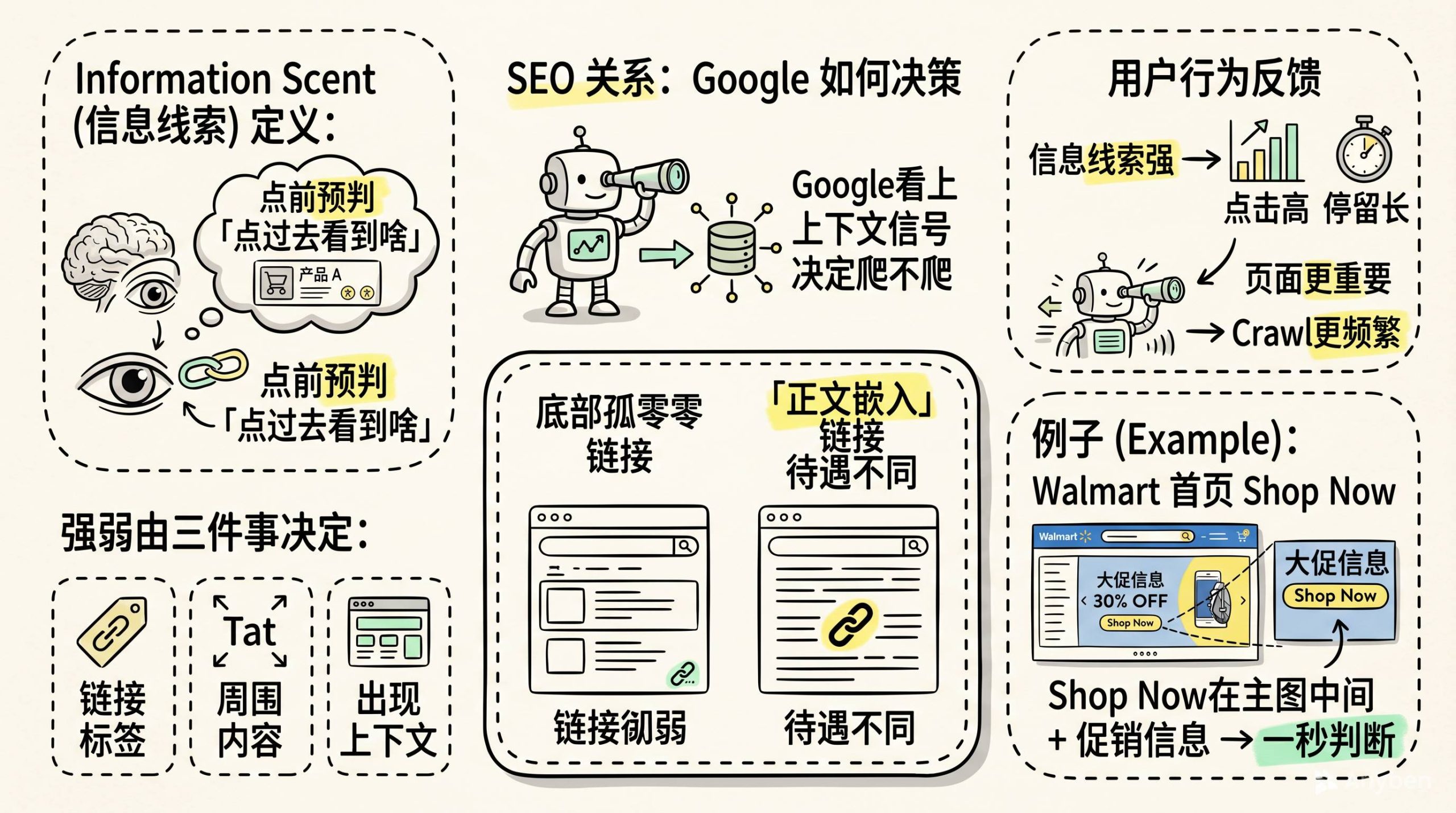
Nielsen Norman Group提过一个概念叫information scent。
翻译过来大概就是:用户在点一个链接之前,心里会预判“点过去大概能看到什么”。这个预判的准确性,就是信息线索的强弱。
链接标签、周围内容、链接出现的上下文。三个东西决定了用户点不点。
听起来是UX的事,跟SEO有什么关系?
关系很大。
Google在判断一个链接值不值得爬的时候,会看这个链接的上下文信号。一个埋在页面底部、周围没有相关内容的孤零零的链接,和一个嵌在正文中间、上下文清晰的链接,bot对待它们的方式不一样。
而且用户行为会反馈给Google。一个信息线索强的链接,点击率高,停留时间长,Google自然会认为这个页面重要,crawl频率也会提高。
所以做内链别光想着bot。想想人。一个真实用户看到这个链接,知不知道点过去是什么?点过去之后会不会失望?
Walmart首页那个“Shop Now”按钮放在主图中间,周围全是促销信息,用户一秒判断。这就是强信息线索。
— 5 —
站点大了,别把crawl depth搞成KPI
有一点得说清楚。
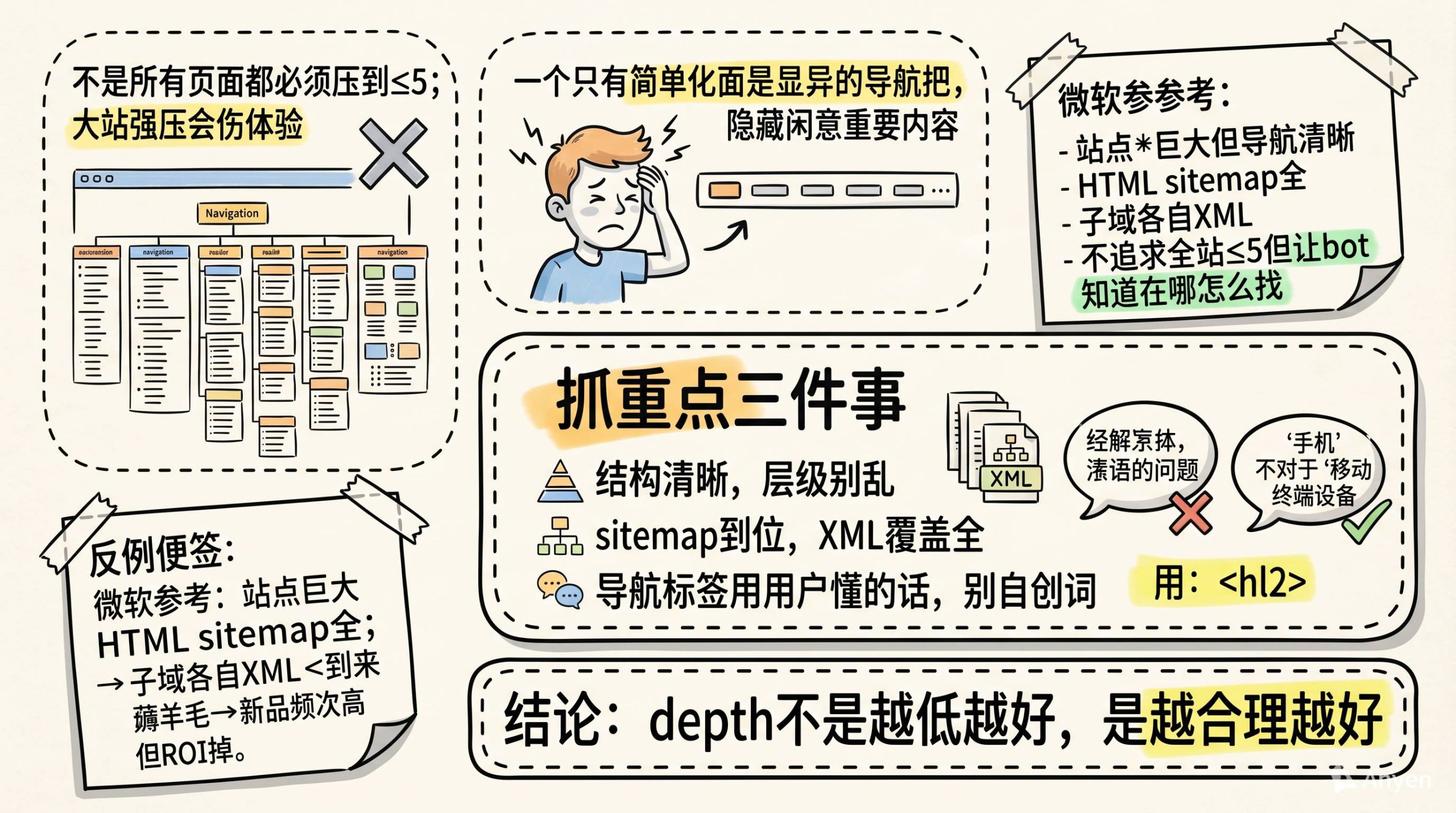
不是所有页面都必须把depth压到5以内。
有些站点太大了,强行压depth反而会让用户体验变差。你想想,如果微软把所有页面都塞到首页5次点击以内,那个导航栏得变成什么样。
这种情况,抓重点:
-
站点结构理清楚,层级关系别乱
-
sitemap做到位,特别是XML sitemap要覆盖全
-
导航标签用用户能看懂的话,别自己发明词汇
微软的做法可以参考。站点巨大,但导航清晰,HTML sitemap做得全,多个子域名各有各的XML sitemap。他们没有追求所有页面depth都在5以内,但他们让bot知道“这些页面在哪里、怎么找到”。
crawl depth不是越低越好,是越合理越好。
— 6 —
经常更新的页面,让它离首页近一点
这个逻辑很简单。
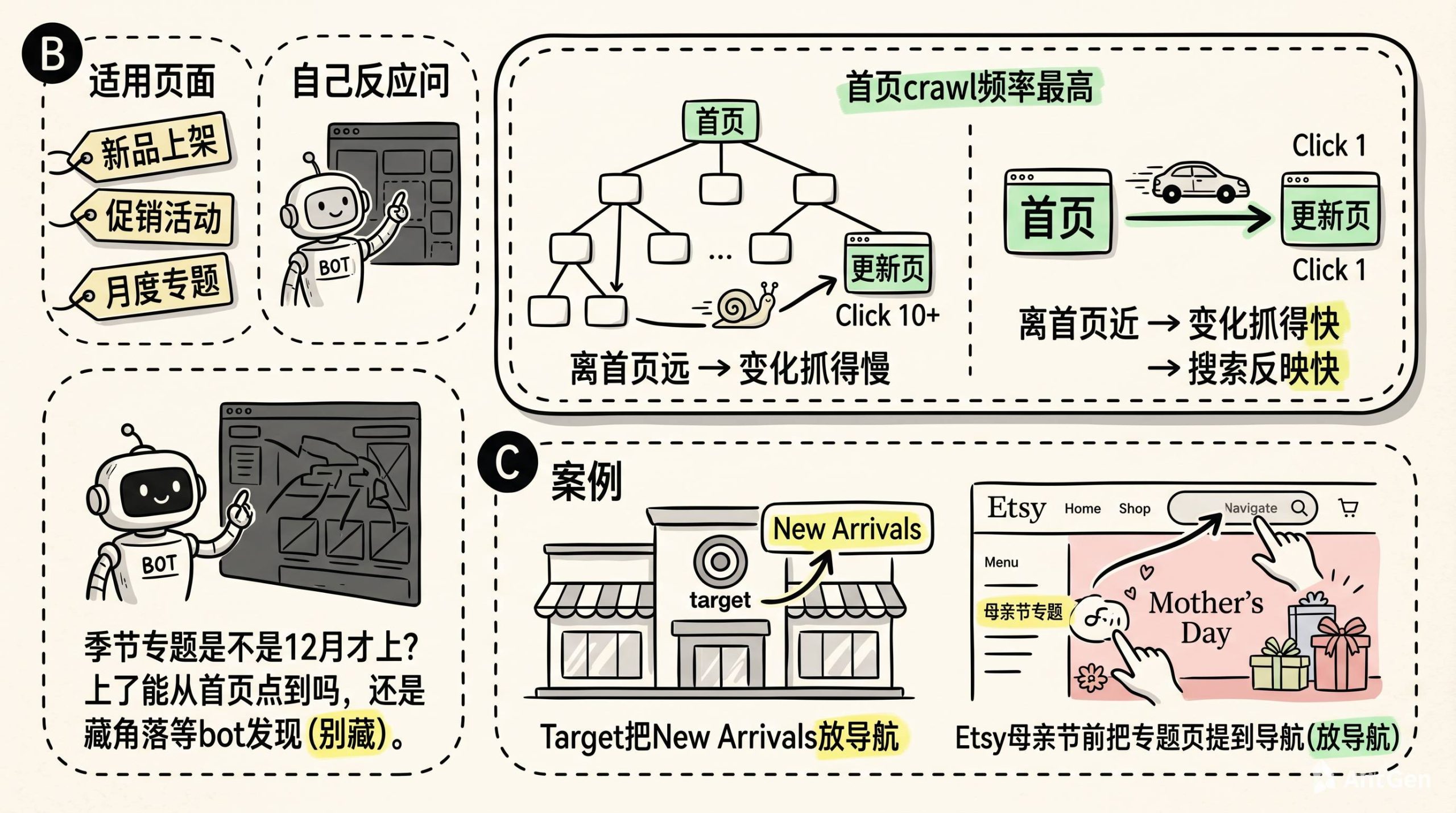
如果你有页面会频繁更新,比如新品上架页、促销活动页、博客的月度专题,这些页面需要Google快速重新索引。让它们从首页就能直接点到。
Target的“New Arrivals”页面永远在导航栏里。Etsy到母亲节前,会把母亲节专题页提到导航栏上。
为什么?
因为首页的crawl频率是最高的。离首页越近,bot每次来都能看到变化。变化被捕捉得越快,页面在搜索结果里反映得越快。
你想想自己独立站上那些“季节性内容”。圣诞专题是不是等到12月才放出来?放出来之后,是从首页能点到,还是藏在某个角落等bot慢慢发现?
— 7 —
分页问题不大,但忽略就是雷
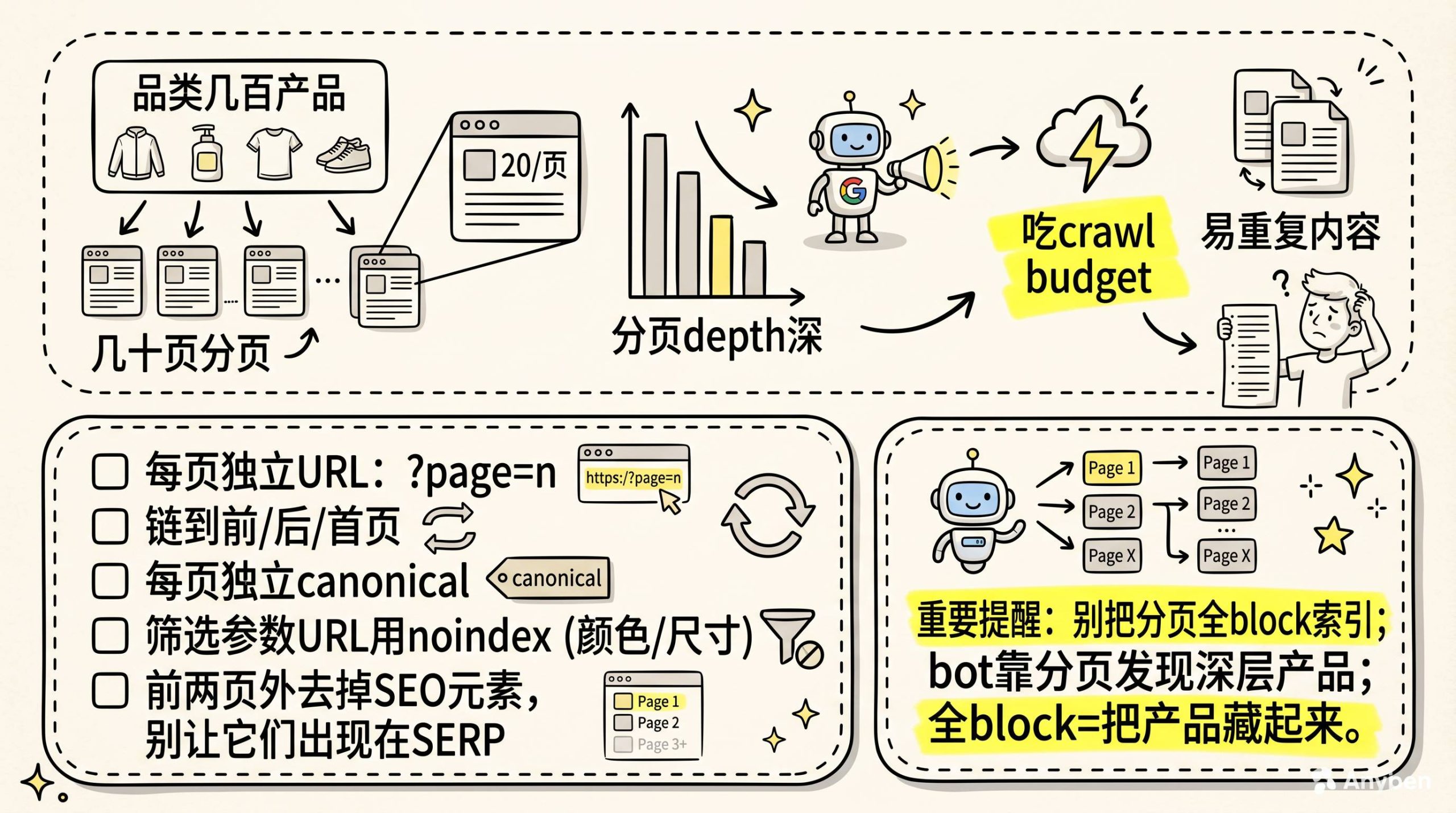
电商站一定有这个问题。
一个品类下面几百个产品,一页放20个,几十页分页。分页页面的crawl depth天然就深。不处理,就会吃掉大量crawl budget,而且容易产生重复内容。
几个实操点:
-
每页给独立URL,用?page=n这种参数
-
每一页都要有链到前一页、后一页、第一页的链接
-
每页设独立canonical URL,别让Google觉得这些页面是重复内容
-
带筛选参数的URL用noindex,比如按尺寸、颜色筛选出来的页面,别让bot去爬
-
前两页以外的分页页面,去掉SEO元素,别让它们在搜索结果里出现
特别注意:不要让分页页面被完全阻止索引。bot是通过分页链接发现深层产品的。你把分页全block了,等于把你自己的产品藏起来了。
— 8 —
URL库存这件事,很少有人提
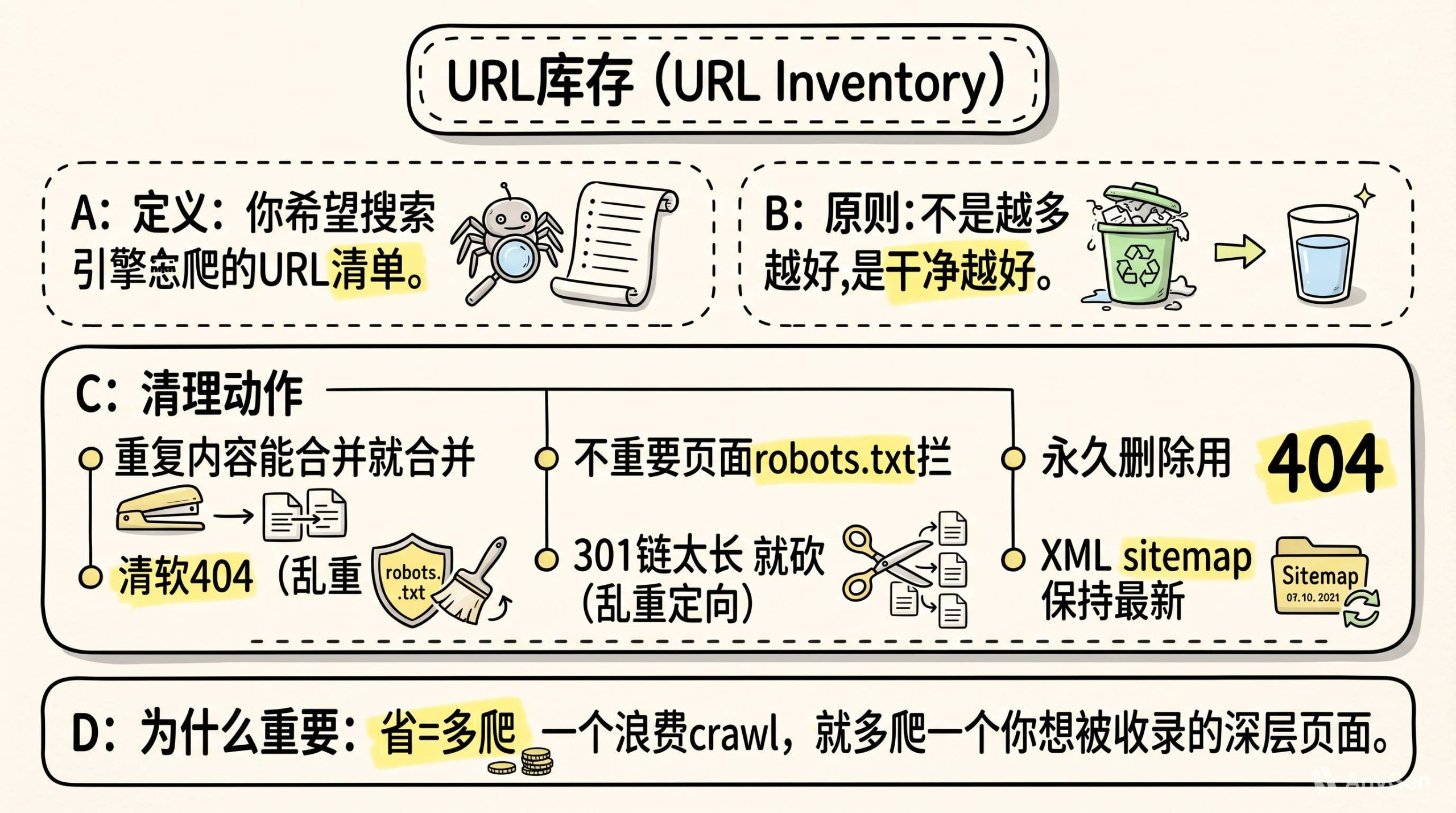
Google有个说法叫URL inventory。
就是你希望搜索引擎爬的URL清单。
这个清单不是越多越好。是越干净越好。
定期清理。
-
重复内容能合并就合并
-
不重要页面用robots.txt拦住
-
永久删除的页面直接用404或410状态码
-
软404(重定向到不相关内容)一定要清
-
301重定向链太长就砍掉
-
XML sitemap保持最新
为什么这件事重要?
因为你每省下一个被浪费的crawl,Googlebot就能多爬一个你想让它爬的页面。那些depth很深但你很想让Google收录的页面,能不能被爬到,很多时候就看这里省没省出budget。
— 9 —
断链对crawl depth的伤害被低估了
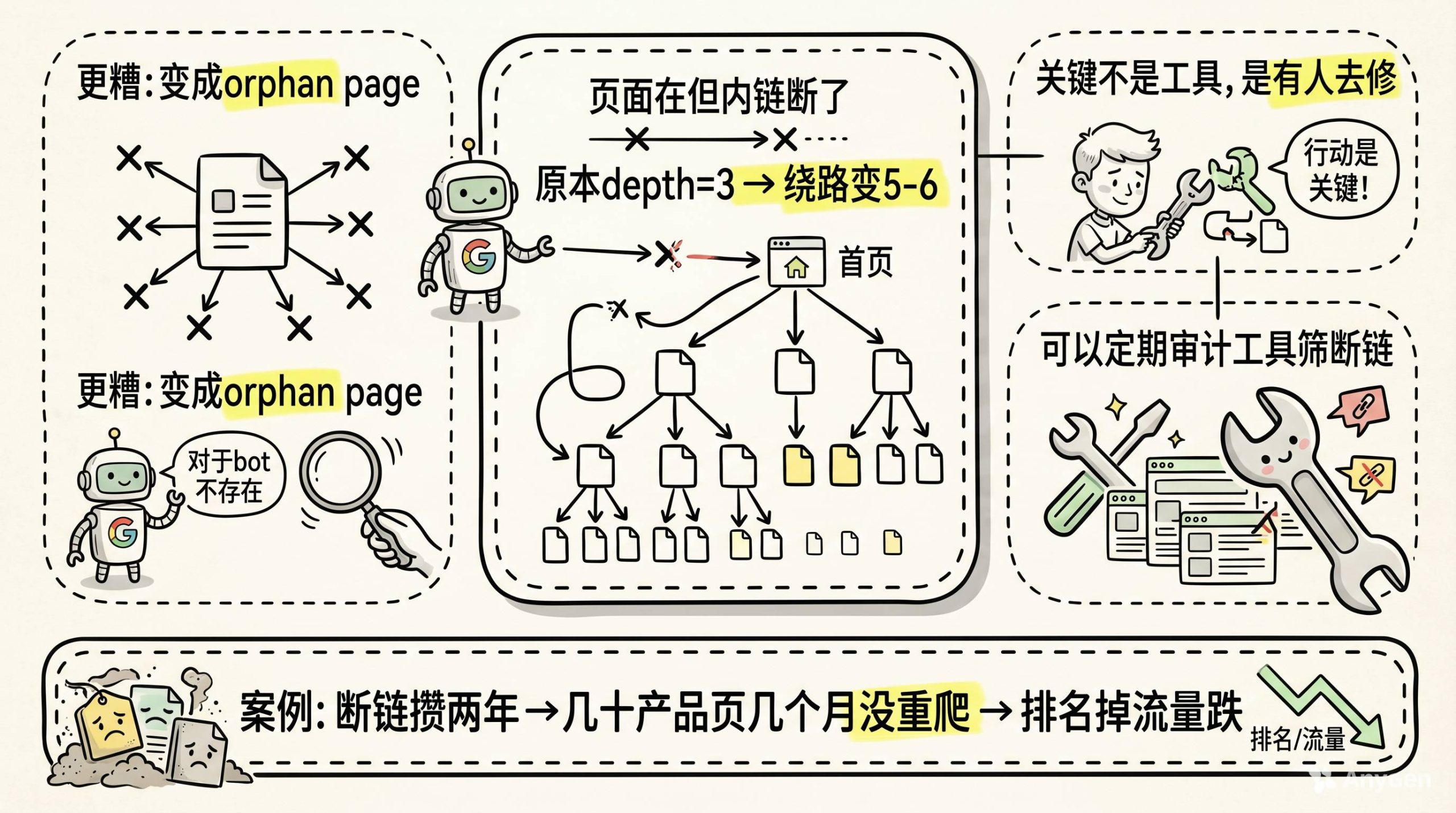
一个页面存在,但指向它的内链断了。
它可能本来depth是3。但因为那条链路断了,bot得绕路,实际depth变成了5、6。更差的情况,这个页面直接变成orphan page,再也没人(没bot)能找到它。
有些工具可以跑定期审计,把断链筛出来。
但工具只是第一步。关键是得有人去修。
我见过一个站,断链攒了快两年没人管。最后去修的时候,发现几十个产品页已经好几个月没被重新爬过了。排名掉的掉,流量跌的跌。
修断链这件事没有技术含量。它只有一个难点:得有人记着做。
— 10 —
最后,看一眼GSC的索引覆盖率
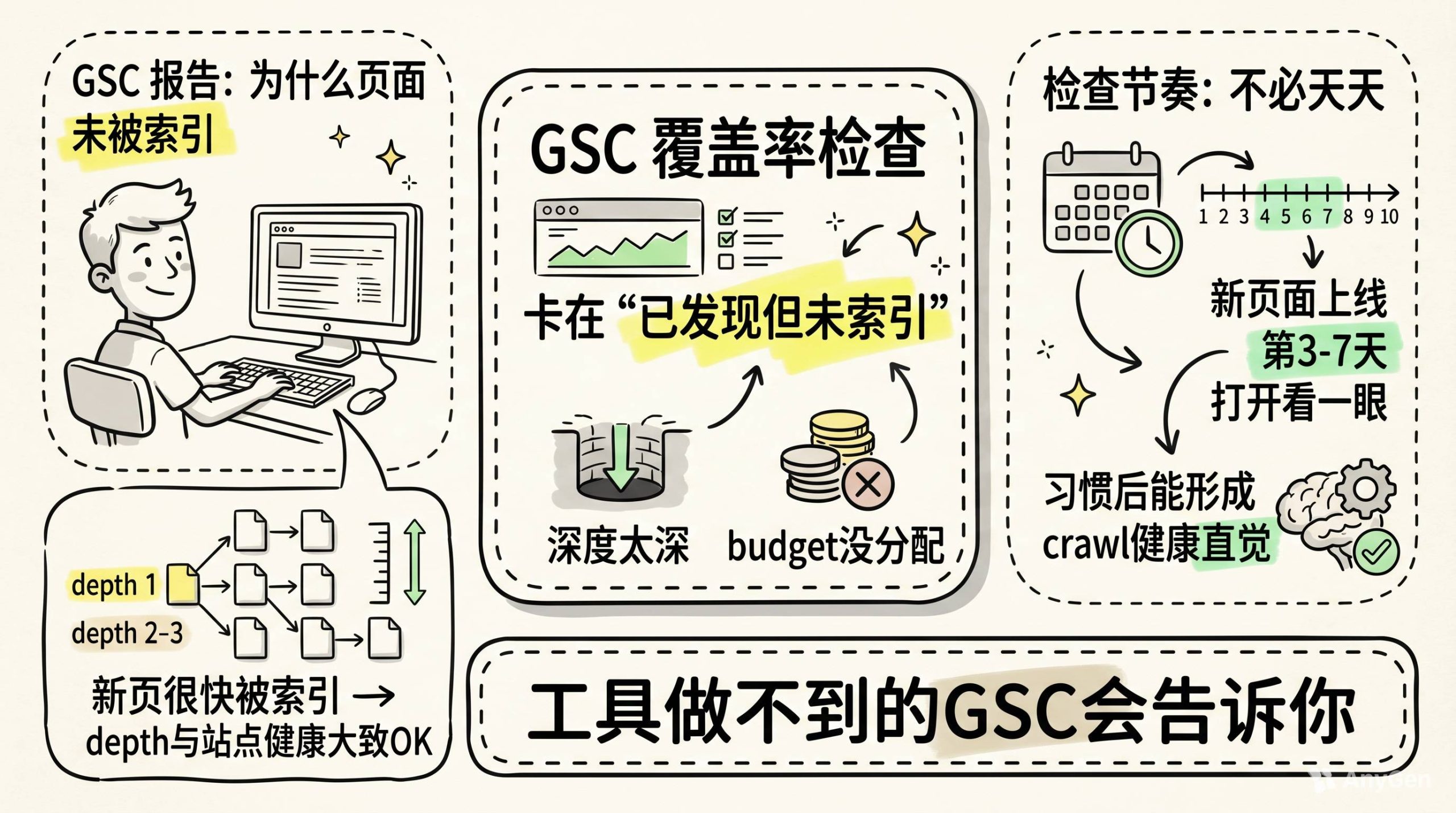
工具能自动化很多东西。但GSC里那个“为什么页面未被索引”的报告,值得你人工点进去看。
有些问题工具不会告诉你。但GSC会。
新页面上了之后,如果很快被索引,说明你的crawl depth和站点健康度大致没问题。如果新页面一直卡在“已发现但未索引”,那大概率是深度太深或者budget没分配过来。
这个检查不需要每天做。但上新页面之后的第3到第7天,打开看一眼。习惯了之后,你对站点的crawl健康度会有一个直觉判断。
— 11 —
再啰嗦几句
站点速度也跟crawl budget有关。页面加载越快,bot单次爬取的页面就越多。PageSpeed Insights跑一遍,目标2秒以内。但这个话题展开就远了,另说。
Crawl depth这件事,单独拿出来讲的人不多。但做独立站久了就会明白,很多“内容不收录”“做了页面没排名”的问题,根源不在内容,不在外链,就在这里。
bot找不到你。
你做得再好也没用。
更多最新文章,请关注公众号:SEOWE跨境说
